『pytorch & 深層学習プログラミング』 備忘録3章





▪次第に怪しくなる雲行き
Yp(Yの予測値)を、学習させる前の段階で出してみた。すると、体重を予想しているはずなのに身長の様な値が出てきてしまった。これは、学習前なので仕方ないかと思い次に進む。

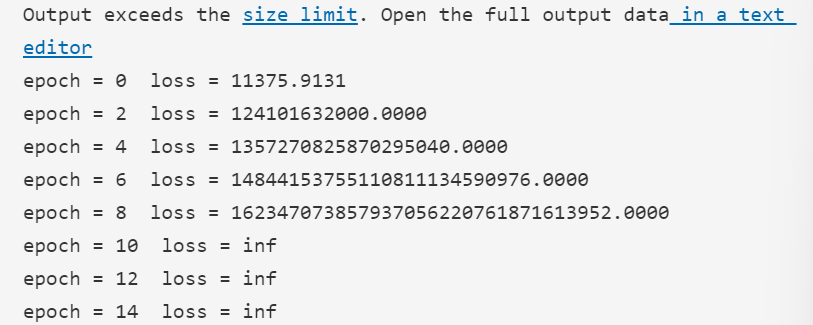
次に、本命の平均二乗誤差である。ここで損失を求めると、かなり大きな値が出てしまった。でも、今後学習をしていけばこの損失も指数関数的に小さくなるだろうと願い次に進む。
勾配計算を行った。WもBも相当大きな値である。とても体重を予想するパラメータではないように思えるが、コンピューターを侮ってはいけない。ここから膨大な学習を経て、最適解に近づくはずである。

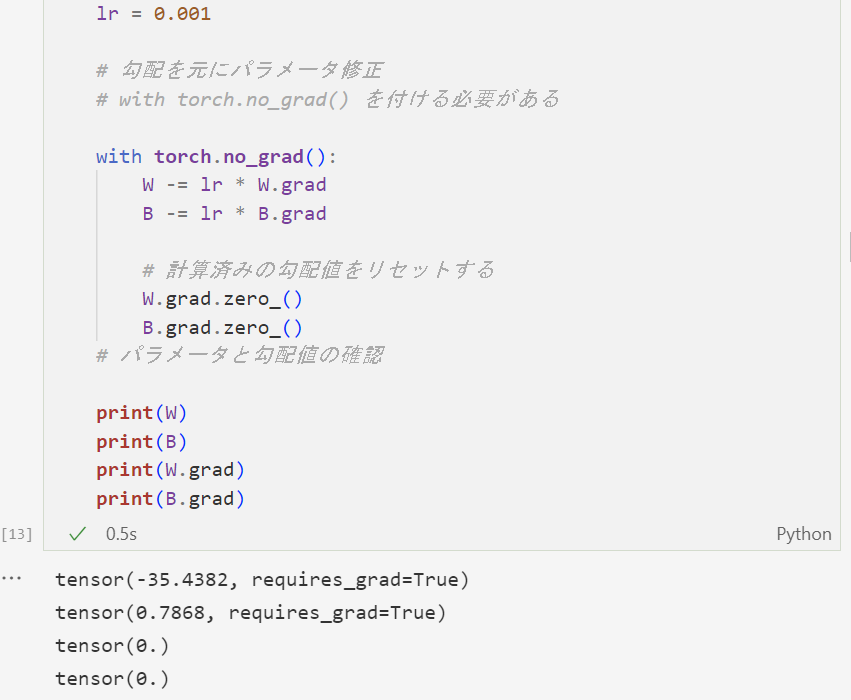
学習率を定義し、パラメータを確認してみる。するとどうだろう、少しはまともな値に近づいた気がしなくもない。